(更新:2020/07)Pandas - Excel/CSV読み書きしてデータ解析
(更新:2020/06)PyODBC - Microsoft Access DBファイルを読んでみる
(作成:2013/12)これまでそれなりに色々なプログラミング言語やスクリプトを使ってきたけれど、個人用途〜仕事効率化として、此頃はshとPythonに落ち着いた感じ。
というわけでPython。良いねこれ……実に良い。
紹介とかハウツーは別に良質なサイトが幾らでもあるのでそちらにお任せするとして、ここではウチの備忘録的に適当な事を書いていくので悪しからず。
pydoc - ドキュメント生成式コメント表記
Pythonではコメントの書き方でドキュメントまで出来ちゃう。仕様書≒ソース、みたいな作り方は日曜大工的なウチにもぴったりで素晴しい。
主なところではこんな書き方をすれば良い。上がソースコード、下がpydocによるドキュメント。良い感じ。
#! /usr/bin/env python
# -*- coding:utf-8 -*-
""" [NAME] に続くScriptの簡易説明文
[DESCRIPTION] Scriptの詳細説明文
"""
__author__ = 'Riyo'
__version__ = '0.1'
import sys
foo = 'bar: '
class MyClass:
"""
[CLASSES] Class説明文
"""
def __init__(self, hoge=''):
""" [CLASSES] 関数説明文
Keyword arguments:
hoge -- 引数説明
"""
self.hoge = hoge
def fuga(self):
""" [CLASSES] 関数説明文
Return value:
戻り値説明
"""
global foo
return foo + self.hoge
def main():
""" [FUNCTIONS] 関数説明文
"""
c = MyClass('piyo')
print c.fuga()
sys.exit(0)
if __name__ == '__main__':
main()# pydoc ./test.py
Help on module test:
NAME
test - [NAME] に続くScriptの簡易説明文
FILE
/home/riyo/bin/test.py
DESCRIPTION
[DESCRIPTION] Scriptの詳細説明文
CLASSES
MyClass
class MyClass
| [CLASSES] Class説明文
|
| Methods defined here:
|
| __init__(self, hoge='')
| [CLASSES] 関数説明文
|
| Keyword arguments:
| hoge -- 引数説明
|
| fuga(self)
| [CLASSES] 関数説明文
|
| Return value:
| 戻り値説明
FUNCTIONS
main()
[FUNCTIONS] 関数説明文
DATA
__author__ = 'Riyo'
__version__ = '0.1'
foo = 'bar: '
VERSION
0.1
AUTHOR
RiyoWindows環境の場合、以下のようなバッチファイルを%PATH%の通ったフォルダに作っておけばPyDocの実行が簡単。
(インストールフォルダは色々変わるかも知れないので都度確認してネ)
pydoc.bat
@python "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.8_3.8.1520.0_x64__qbz5n2kfra8p0\Lib\pydoc.py" %*以下test.pyをPyDocに噛ませる場合。ファイル名の.pyは省略しないとダメ。
> pydoc.bat test
Help on module test:
NAME
test - [NAME] に続くScriptの簡易説明文
DESCRIPTION
[DESCRIPTION] Scriptの詳細説明文
CLASSES
MyClass
...optparse - コマンドラインオプション実装
スクリプトでコマンドラインを実装するには optparse を使うと楽で良い。何が素敵って、 [-h|--help] や --version も簡単に実装できて、例外処理もよろしくやってくれるって事。
惜しむらくは複数行にわたるhelpメッセージを付けられない事か……まあ詳細なんかは man とか作るだろうし、これで十分だけれど。
なおこれを利用するにあたっては、コマンドラインオプションのBackgroundを理解しておくと後々役立つ。
#! /usr/bin/env python
# -*- coding:utf-8 -*-
import sys
from optparse import OptionParser
from optparse import OptionGroup
def main():
psr = OptionParser(version='0.1')
psr.add_option('-a', '--apple', dest='apple',
help = u'りんご')
psr.add_option('-b', '--banana', action='store_true', dest = 'banana',
help = u'ばなな')
psr.add_option('-c', '--cherry', action='count', dest = 'cherry',
help = u'さくらんぼ')
grp = OptionGroup(psr, 'Note',
u'くだものぱくぱく。')
psr.add_option_group(grp)
(opts, args) = psr.parse_args()
if opts.apple != None:
print u'りんごの感想: %s' % opts.apple
if opts.banana:
print u'そんなばななー'
if opts.cherry != None:
print 'いやしんぼめ、もう%d粒も食べおって' % opts.cherry
sys.exit(0)
if __name__ == '__main__':
main()$ ./test.py -a delicious!
りんごの感想: delicious!
$ ./test.py --banana
そんなばななー
$ ./test.py -ccccc
いやしんぼめ、もう5粒も食べおって
$ ./test.py -a
Usage: test.py [options]
test.py: error: -a option requires an argument
$ ./test.py --help
Usage: test.py [options]
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-a APPLE, --apple=APPLE
りんご
-b, --banana ばなな
-c, --cherry さくらんぼ
Note:
くだものぱくぱく。
$ ./test.py --version
0.1telnetlib - Python ScriptでTelnet操作
pexpect モジュールのTelnet拡張? なんだろうなぁ。便利なのは良い事だ。コードはこんな感じ。
#! /usr/bin/env python
# -*- coding:utf-8 -*-
import sys
import telnetlib
def main():
HOST = 'hostname'
LOGIN_USER = 'account'
LOGIN_PASS = 'password'
ENABLE_PASS = 'admin_password'
try:
tn = telnetlib.Telnet(HOST)
tn.set_debuglevel(0)
# login
tn.read_until('Username:')
tn.write(LOGIN_USER + 'n')
tn.read_until('Password:')
tn.write(LOGIN_PASS + 'n')
# enable
tn.write('en' + 'n')
tn.read_until('Password:')
tn.write(ENABLE_PASS + 'n')
tn.read_until('#')
# show running-config
tn.write('terminal length 0' + 'n')
tn.write('show running-config' + 'n')
cfg = tn.read_until('endrn').splitlines()
tn.write('exit' + 'n')
tn.read_until('#')
except EOFError:
print 'connection closed.'
for line in cfg:
print line
sys.exit(0)
if __name__ == '__main__':
main()上述の例は、Ciscoネットワーク機器にTelnetでアクセスして、現在動作中の configure を出力するというもの。単なるサンプルスクリプトなのでアカウント情報をコード中に記述しているけれど、平文なので注意。まあコマンドラインオプションで取るのが妥当だろうねえ。
基本は read_until() でコマンドラインに出力される可能性のある文字列を待ち、 write() で入力したい文字列を与える。これの繰り返し。
set_debuglevel() は、引数に0以上の数値を仕込めば stdout に telnetlib の実行結果を出力してくれる。物凄く確認し辛いけれど、テスト実行なんかでまあ便利。
Telnetで管理する同一機材が沢山あったりすると、一括パスワード変換や同一設定の一括登録なんか手作業でやるの莫迦らしくてねえ。こんなん使って適当にスクリプトを組んで、for でホスト名羅列したタプルぶん回せば、仕事がすこぶる捗る。お勧め。
PyODBC - Microsoft Access DBファイルを読んでみる
ここではこんなテストデータで試してみる。
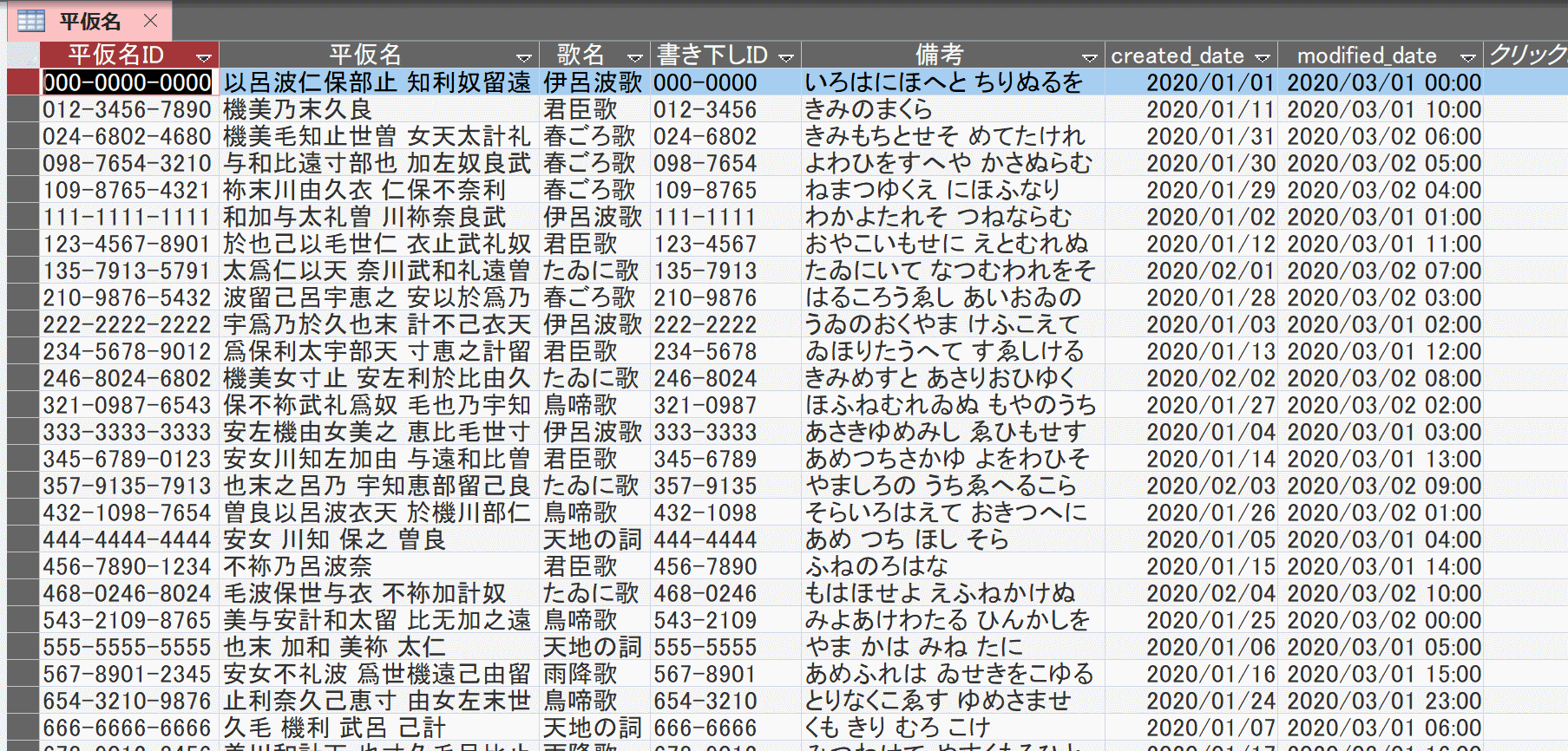
\データ内容は気にするな!/
PyODBC使うのでpipでパッケージ入れる。
> pip install pyodbc
Collecting pyodbc
Downloading pyodbc-4.0.30-cp38-cp38-win_amd64.whl (68 kB)
|████████████████████████████████| 68 kB 1.3 MB/s
Installing collected packages: pyodbc
Successfully installed pyodbc-4.0.30odbcad32.exeての実行して[ドライバー]タブを見たときに「Microsoft Access Driver (.mdb, .accdb)」というエントリが無いようならMicrosoft Access データベース エンジン 2010 再頒布可能コンポーネントもインストールが必要。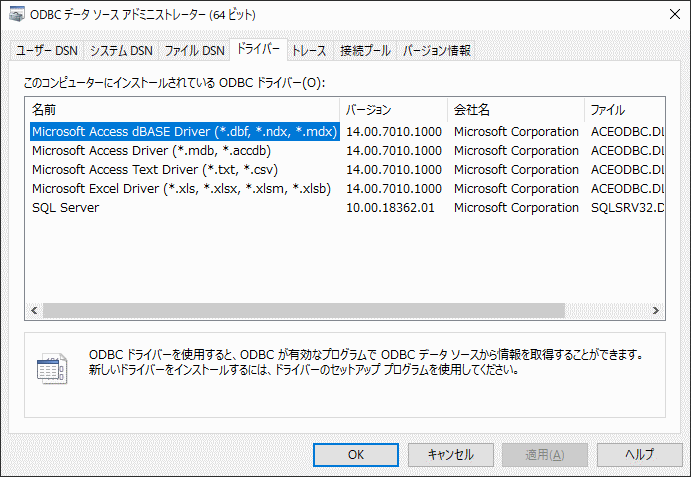
で、コード。
#! /usr/bin/env python
# -*- coding: utf-8 -*-
""" Microsoft Access(*.mdb, *.accdb)を読み込むテスト。
"""
import pyodbc
def get_msaccdata(fname, query):
""" Accessファイルからクエリ指定でデータを取得する。
Keyword arguments:
fname -- Accessファイル名
query -- SQLクエリ
Return value:
取得データ
"""
conn_str = (
r'DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};'
r'DBQ=' + fname + ';'
)
cnxn = pyodbc.connect(conn_str)
crsr = cnxn.cursor()
crsr.execute(query)
ret = crsr.fetchall()
crsr.close()
cnxn.close()
return ret
def main():
""" メイン関数
"""
CURRENT = 'C:\common\home\Scripts\'
fname_reg = CURRENT + 'いろは歌.accdb'
q = 'SELECT 備考 FROM 平仮名 ORDER BY modified_date'
data = get_msaccdata(fname_reg, q)
print(data)
if __name__ == '__main__':
main()実行結果。
> python readAccessDB.py
[('いろはにほへと ちりぬるを', ), ('わかよたれそ つねならむ', ), ('うゐのおくやま けふこえて', ), ('あさきゆめみし ゑひもせす', ), ('あめ つち ほし そら', ), ('やま かは みね たに', ), ('くも きり むろ こけ', ), ('ひと いぬ うへ すゑ', ), ('ゆわさる おふせよ', ), ('えの�を なれゐて', ), ('きみのまくら', ), ('おやこいもせに えとむれぬ', ), ('ゐほりたうへて すゑしける', ), ('あめつちさかゆ よをわひそ', ), ('ふねのろはな', ), ('あめふれは ゐせきをこゆる', ), ('みつわけて やすくもろひと', ), ('おりたちうゑし むらなへ', ), ('そのいねよ まほにさかえぬ', ), ('あめつちわき かみさふる', ), ('ひのもとなりて ゐやしろを', ), ('おほむへゆには うらまけね', ), ('これそたえせぬ すゑいくよ', ), ('とりなくこゑす ゆめさませ', ), ('みよあけわたる ひんかしを', ), ('そらいろはえて おきつへに', ), ('ほふねむれゐぬ もやのうち', ), ('はるころうゑし あいおゐの', ), ('ねまつゆくえ にほふなり', ), ('よわひをすへや かさぬらむ', ), ('きみもちとせそ めてたけれ', ), ('たゐにいて なつむわれをそ', ), ('きみめすと あさりおひゆく', ), ('やましろの うちゑへるこら', ), ('もはほせよ えふねかけぬ', )]こんな感じ。
Pandas - Excel/CSV読み書きしてデータ解析
こちらもお仕事都合で調べたものを。といっても紹介用にはあまり良いデータも無いので、どっちかといえばPandas使ってExcelやCSVデータを好きなように読んだり整理したり書き込んだりって方がメインになるかも。データ解析に特価したPandasが泣いてるんやな。なお本当にExcel/CSV読み書きだけなら直接OpenPyxlとかxlrd/xlwt使った方が余程高速だと思いマス。
いきなり参考サイトだけど、Pandas / Numpy関連のノウハウは下記サイトがとても良く纏まっていて素敵です。ウチもだいたいここで使い方を知りました。
参考:
pnpでPandasとxlrd入れるよ。何か一緒に色々入る。Numpyは後でちょっと振れるかも。
> pip install pandas
Collecting pandas
Downloading pandas-1.0.5-cp38-cp38-win_amd64.whl (8.9 MB)
|████████████████████████████████| 8.9 MB 2.2 MB/s
Collecting pytz>=2017.2
Downloading pytz-2020.1-py2.py3-none-any.whl (510 kB)
|████████████████████████████████| 510 kB 6.8 MB/s
Collecting numpy>=1.13.3
Downloading numpy-1.19.0-cp38-cp38-win_amd64.whl (13.0 MB)
|████████████████████████████████| 13.0 MB ...
Collecting python-dateutil>=2.6.1
Downloading python_dateutil-2.8.1-py2.py3-none-any.whl (227 kB)
|████████████████████████████████| 227 kB ...
Collecting six>=1.5
Downloading six-1.15.0-py2.py3-none-any.whl (10 kB)
Collecting xlrd
Downloading xlrd-1.2.0-py2.py3-none-any.whl (103 kB)
|████████████████████████████████| 103 kB 2.2 MB/s
SInstalling collected packages: pytz, numpy, six, python-dateutil, pandas、 xlrd
WARNING: The script f2py.exe is installed in 'C:UsersriyoAppDataLocalPackagesPythonSoftwareFoundation.Python.3.8_qbz5n2kfra8p0LocalCachelocal-packagesPython38Scripts' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed numpy-1.19.0 pandas-1.0.5 python-dateutil-2.8.1 pytz-2020.1 six-1.15.0何はともあれExcel読んでみる。
#! /usr/bin/env python
# -*- coding: utf-8 -*-
""" PandasでExcelとかCSVとか弄るテスト。
"""
import pprint
import pandas as pd
def main():
""" メイン関数
"""
CURRENT = 'C:\common\home\Scripts\'
fname_xlsx = 'いろは歌.xlsx'
fname_csv1 = 'いろは歌.csv'
fname_csv2 = '書き下し.csv'
fname_csv3 = '平仮名.csv'
# Excel読込。シート指定はsheet_nameで。無ければ最初のシートが読まれる。
xlsx_df = pd.read_excel(CURRENT + fname_xlsx, sheet_name='平仮名')
print(xlsx_df[['平仮名', '備考']])
if __name__ == '__main__':
main()長いので省略してるけど結果。
> python testPandas.py
平仮名 備考
0 以呂波仁保部止 知利奴留遠 いろはにほへと ちりぬるを
1 和加与太礼曽 川袮奈良武 わかよたれそ つねならむ
2 宇爲乃於久也末 計不己衣天 うゐのおくやま けふこえて
3 安左機由女美之 恵比毛世寸 あさきゆめみし ゑひもせす
(省略)
31 太爲仁以天 奈川武和礼遠曽 たゐにいて なつむわれをそ
32 機美女寸止 安左利於比由久 きみめすと あさりおひゆく
33 也末之呂乃 宇知恵部留己良 やましろの うちゑへるこら
34 毛波保世与衣 不袮加計奴 もはほせよ えふねかけぬ今度はCSV読んでみる。コードは読込処理のトコロのみ。
# CSV読込。dtype=strしとくと、電話番号みたく頭文字が0の場合に数字セルと勘違いされない。
# encoding='utf-8'は文字コード処理。日本語CSVの文字コードによっては'cp932'なんかも。
csv1_df = pd.read_csv(CURRENT + fname_csv1, dtype=str, encoding='utf-8')
csv2_df = pd.read_csv(CURRENT + fname_csv2, dtype=str, encoding='utf-8')
csv3_df = pd.read_csv(CURRENT + fname_csv3, dtype=str, encoding='utf-8')
print(csv1_df[['歌名', '作者']])
print(csv2_df[['書き下し']])
print(csv3_df[['平仮名', '備考']])こちらも省略形だけど結果。
> python testPandas.py
歌名 作者
0 伊呂波歌 不明
1 天地の詞 不明
(省略)
6 春ごろ歌 堀田六林
7 たゐに歌 不明
書き下し
0 色は匂へど散りぬるを
1 我が世誰そ常ならむ
2 有為の奥山今日越えて
3 浅き夢見し酔ひもせず
(省略)
31 田居に出で 菜摘む我をぞ
32 君召すと 漁り追ひゆく
33 山城の うち酔へる子ら
34 藻葉乾せよ え舟繁けぬ
平仮名 備考
0 以呂波仁保部止 知利奴留遠 いろはにほへと ちりぬるを
1 和加与太礼曽 川袮奈良武 わかよたれそ つねならむ
2 宇爲乃於久也末 計不己衣天 うゐのおくやま けふこえて
3 安左機由女美之 恵比毛世寸 あさきゆめみし ゑひもせす
(省略)
31 太爲仁以天 奈川武和礼遠曽 たゐにいて なつむわれをそ
32 機美女寸止 安左利於比由久 きみめすと あさりおひゆく
33 也末之呂乃 宇知恵部留己良 やましろの うちゑへるこら
34 毛波保世与衣 不袮加計奴 もはほせよ えふねかけぬ良い感じ。
Python Tips
グローバル変数の使い方
Pythonでグローバル定義をClass内や関数内で正しく使う方法。
>>> hoge = ['a', 'b', 'c']
>>>
>>> def test():
... hoge = 'a'
... print hoge
...
>>> test()
a
>>> print hoge
['a', 'b', 'c']
>>>
>>> def test():
... global hoge
... hoge = 'a'
... print hoge
...
>>> test()
a
>>> print hoge
aちゃんと区別されてるねって話。
文字列操作 - 特定複数の「文字」を消す
関数単体であるかなと思ったら無かったのでこんな感じで。以外とトリッキー。
>>> import string
>>>
>>> hoge = '01-23-45-67-89-AB, 01:23:45:67:89:AB, 0123.4567.89AB'
>>>
>>> hoge = hoge.translate(string.maketrans('', ''), '.:-')
>>> print hoge
0123456789AB, 0123456789AB, 0123456789AB