(作成:2013/11)
サーバの冗長化環境を作るためにMySQLをレプリケーションしたりlsyncdでファイル同期をしておくのも大事なんだけれど、実際にサーバ障害発生したらどうなのよ、てなわけで。BIG-IPとか持ってたらソレ任せでも良いんだけれど、f5 networks社のは個人じゃ手出し出来ないからナー。元々個人で使うモンじゃねーけど。
Install on CentOS
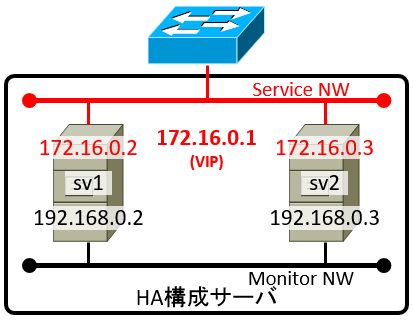
提供するサービスは、あまり良い例ではないけれど仮に
memcached として話を進めよう。要件としてはごくごく単純に、マスタが斃れたらスレイヴを昇格してフェイルオーバ、旧マスタ復活の際にフェイルバックはさせないものとする。NW設定は以下のような感じで。
| (VIP) | sv1 | sv2 | |
|---|---|---|---|
| eth0 | 172.16.0.1 | 172.16.0.2 | 172.16.0.3 |
| eth1 | 192.168.0.2 | 192.168.0.3 |
取り敢えず必要なパッケージを2台のサーバにぶっ込む。EPELなら最新版が導入できるのでそちらで。EPELの使い方は拙サイト「yum」を参照。

# yum install --enablerepo=epel heartbeat
サクッと設定。
#### /etc/ha.d/ha.cf of sv1
logfile /var/log/ha-log
keepalive 2
deadtime 30
warntime 10
initdead 120
udpport 694
ucast eth1 192.168.0.3
auto_failback off
watchdog /dev/watchdog
node sv1
node sv2
ping 172.16.0.254
##respawn hacluster /usr/lib/heartbeat/ipfail
respawn root /usr/local/sbin/ha-chk-memcached.sh
apiauth ipfail gid=haclient uid=hacluster
#### /etc/ha.d/ha.cf of sv2
logfile /var/log/ha-log
keepalive 2
deadtime 30
warntime 10
initdead 120
udpport 694
ucast eth1 192.168.0.2
auto_failback off
watchdog /dev/watchdog
node sv1
node sv2
ping 172.16.0.254
##respawn hacluster /usr/lib/heartbeat/ipfail
respawn root /usr/local/sbin/ha-chk-memcached.sh
apiauth ipfail gid=haclient uid=hacluster
取り敢えずこんな感じの初期設定。違うトコロは ucast のIPアドレス。 ここは冗長化相手のIPアドレスを指定する 。自分のIPじゃないので間違わないように。
ping 172.16.0.254 はサービス側の通信確認用。 respawn はサービス監視コマンドで後述。
これ以降は両サーバ共通設定。さくさく設定しよう。
#### /etc/ha.d/haresources
sv1 memcached 172.16.0.1/24
#### /etc/ha.d/authkeys
auth 1
1 crc
# chmod 600 /etc/ha.d/authkeys
監視コマンドはなるべく穴の無いように作り込みたいね。こんな感じで足りるかな……。
#! /bin/bash
#### /usr/local/sbin/ha-chk-memcached.sh
INTERVAL=30
STB_INTV=40
VIP=172.16.0.1
while true; do
/etc/ha.d/resource.d/IPaddr ${VIP} status >/dev/null 2>&1
if [ $? -ne 0 ]; then
sleep ${INTERVAL}
continue
fi
## Process check
kill -0 `cat /var/run/memcached/memcached.pid` >/dev/null 2>&1
if [ $? -ne 0 ]; then
/usr/lib/heartbeat/hb_standby
fi
(echo 'stats'; sleep 1; echo 'quit'; sleep 1;) | telnet localhost 11211 2> /dev/null | grep -q "STAT pid"
if [ $? -ne 0 ]; then
/usr/lib/heartbeat/hb_standby
fi
sleep ${STB_INTV}
done
無限ループでブン回してチェックするらしい。
L9 IPaddr によるチェックは、自分自身がマスタかどうかを確認している。自分がスレイヴの場合、特にチェックする事は無いので continue 。
L16 kill -0 はプロセス存在確認。L20 は telnet での stats 結果確認。この2つの確認で memcached が使える状態にあるかを判断する。 INTERVAL や STB_INTV はチェック速度に関わるので、サーバ負荷状況を見つつ値を調整しても良いかも。
ここまできたらマスタ、スレイヴ共に起動する。
# /etc/init.d/heartbeat start
動作確認
インタフェースを見てみよう。
(sv1)# /sbin/ifconfig
eth0 Link encap:Ethernet HWaddr XX:XX:XX:XX:XX:XX
...
eth0:0 Link encap:Ethernet HWaddr XX:XX:XX:XX:XX:XX
inet addr:172.16.0.1 Bcast:172.16.0.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
lo Link encap:Local Loopback
...
# ps -ef | grep memcached
...
102 26838 1 0 19:07 ? 00:00:00 memcached -d -p 11211 -u memcached -m 64 -c 1024 -P /var/run/memcached/memcached.pid -v
...
(sv2)# /sbin/ifconfig
eth0 Link encap:Ethernet HWaddr XX:XX:XX:XX:XX:YY
...
(VirtualIP無し)
lo Link encap:Local Loopback
...
# ps -ef | grep memcached
...
(memcachedプロセス無し)
こんな感じで、マスタの方にサービス提供用の仮想IPが割り振られ、/etc/ha.d/haresources で定義した通り memcached が起動している。
ここで sv1 の memcached を手動停止すると、フェイルオーバして立場が逆転する。
(sv1)# /etc/init.d/memcached stop
memcached を停止中: [ OK ]
# /sbin/ifconfig
eth0 Link encap:Ethernet HWaddr XX:XX:XX:XX:XX:XX
...
(VirtualIP無し)
lo Link encap:Local Loopback
...
# ps -ef | grep memcached
...
(memcachedプロセス無し)
(sv2)# /sbin/ifconfig
eth0 Link encap:Ethernet HWaddr XX:XX:XX:XX:XX:YY
...
eth1:0 Link encap:Ethernet HWaddr XX:XX:XX:XX:XX:YY
inet addr:172.16.0.1 Bcast:172.16.0.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
lo Link encap:Local Loopback
...
# ps -ef | grep memcached
...
102 23456 1 0 19:22 ? 00:00:00 memcached -d -p 11211 -u memcached -m 64 -c 1024 -P /var/run/memcached/memcached.pid
てな感じ。これでまた sv2 側で memcached を落とすと、 sv1 側にフェイルオーバしてくれる。
また sv1 側で heartbeat を再起動したりしても、 sv2 → sv1 への切り替わりは発生しない(結果は割愛)。これで auto=failback off の設定が効いている事も確認できる。
もう少し詳しい動作は /var/log/ha-log を参考にすると良い。